
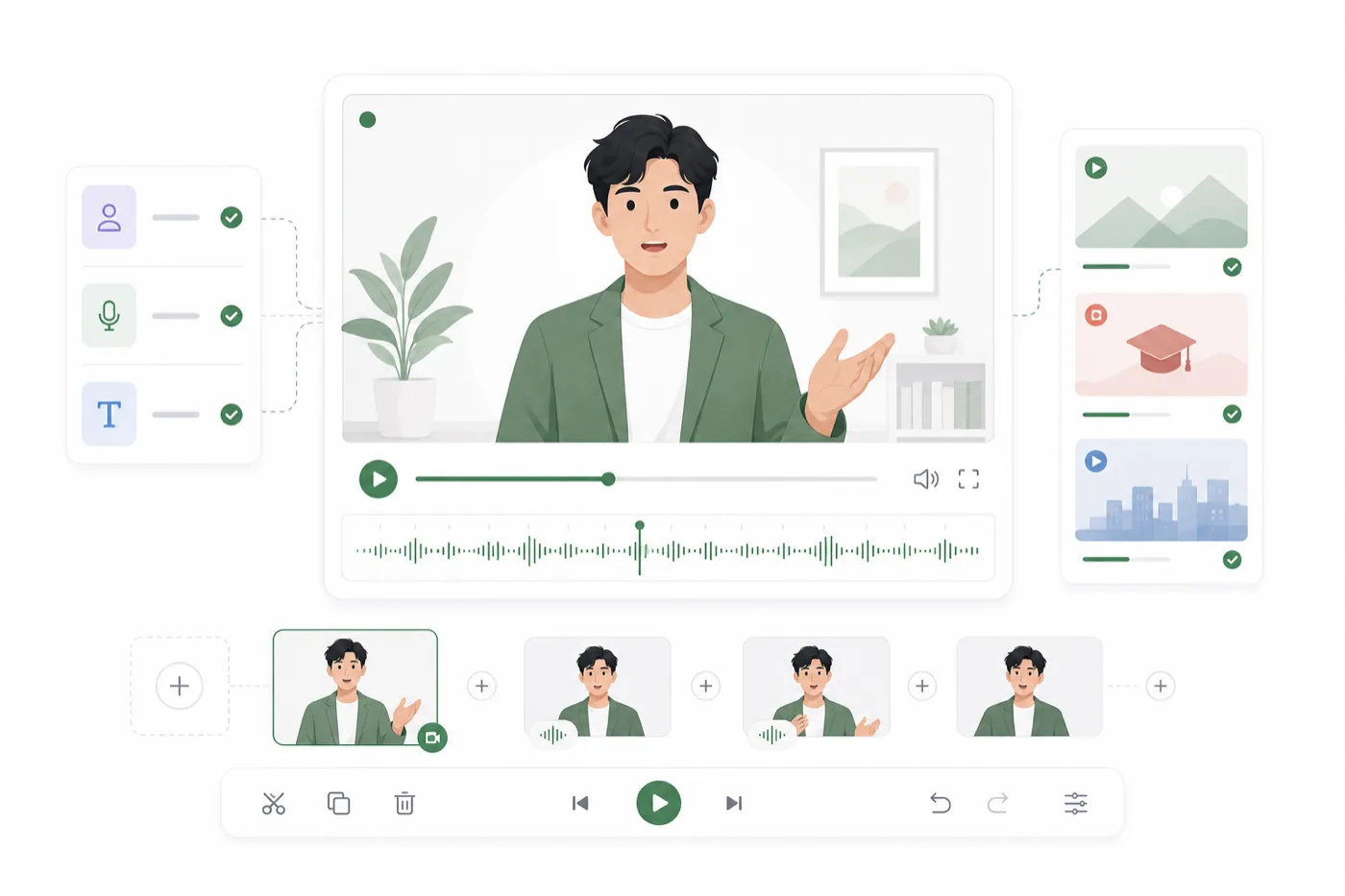
Talking avatar 最好从声音开始做。好的声音表演会给 avatar 提供节奏、情绪和时间线。图片当然重要,但最终视频通常取决于声音是否已经被调整好。
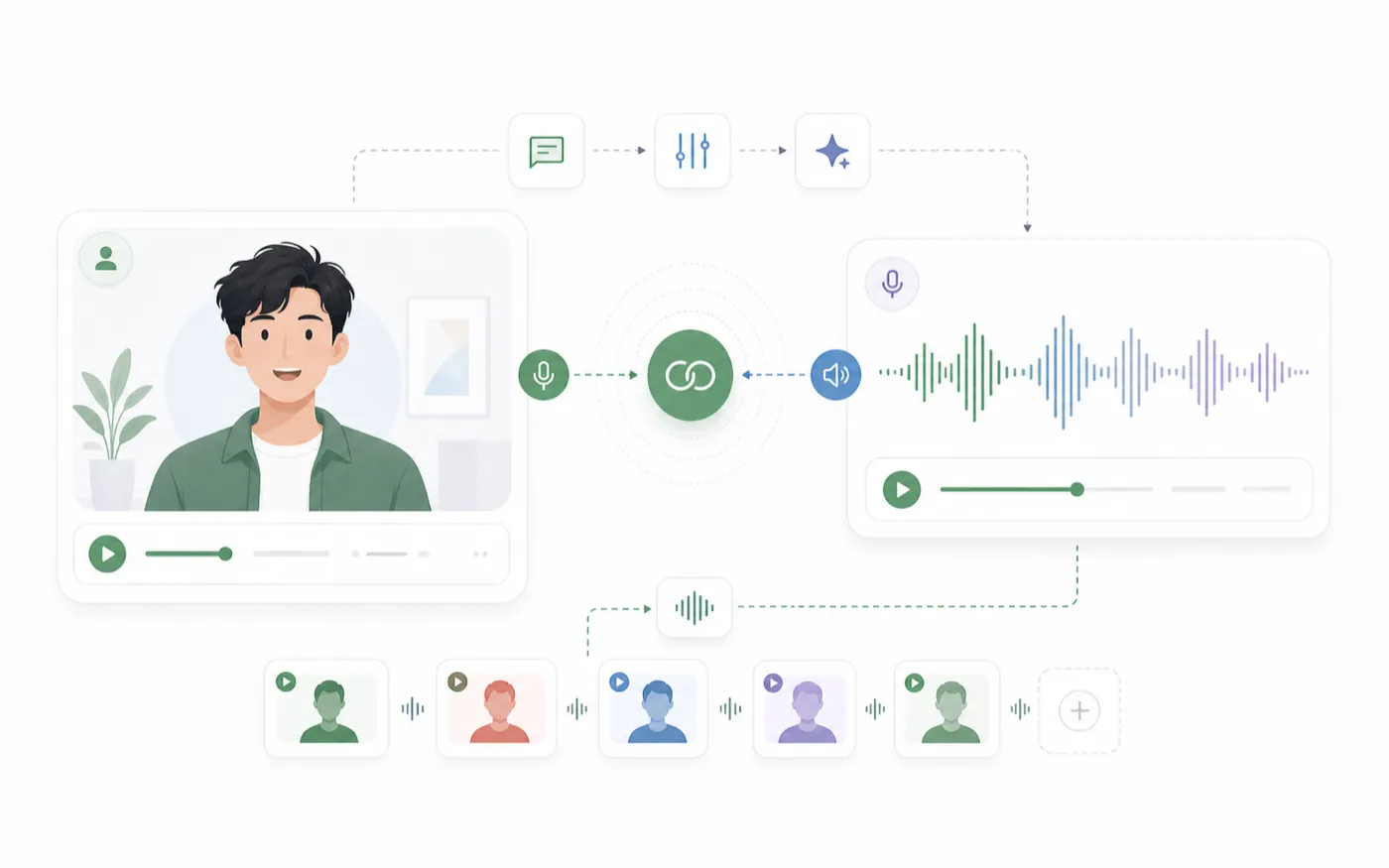
RoleTTS 把声音创作和 avatar 输出连在一起,你可以从脚本到语音再到口型同步视频,不需要在另一个工具里重新搭建上下文。
先做好声音,再做 Avatar
先处理脚本和声音。如果音频很平,avatar 即使图片漂亮也会显得平。如果音频有清晰节奏和情绪,视频的基础就会更稳。
你可以用 AI Text to Speech 生成语音,用 AI Voice Design 设计新音色,或者从 AI Voice Library 使用已保存音色。
脚本要适合视频
Talking avatar 适合更简洁的台词。把长解释拆成短段,这样 avatar 的节奏更自然,观众也更容易跟上。
如果是产品演示,每个片段最好只讲一个点。如果是角色剧情,可以把不同情绪节拍拆成更短的句子。
选择和声音匹配的 Avatar 图片
Avatar 图片应该和声音承担同一个角色。冷静旁白和高能创作者口播,需要完全不同的视觉状态。
尽量使用清晰的人像或角色图,脸部要容易识别。避免脸太小、遮挡太重或视觉信息过于混乱的图片。
![]()
导出前检查声画匹配
导出前可以判断声音和图片是否像同一个人或同一个角色:
- 表情是否适合语气?
- 视觉年龄或风格是否匹配声音?
- 台词长度对 avatar 来说是否自然?
- 不额外解释时,这个片段是否也能成立?
同时检查口型和节奏
脚本干净、音频不赶的时候,口型同步更容易判断。不要只盯嘴型,也要看整体表演。即使口型很准,如果声音节奏和角色视觉不匹配,视频还是会不自然。
声音准备好后,再进入 Talking Avatar 工作流,生成后先预览,再导出。
按发布渠道导出片段
不同渠道需要不同节奏。短视频要更快进入重点,教程可以多一点呼吸感,角色对白则需要更细的情绪节拍和更干净的剪辑。
把效果好的声音和 avatar 组合保存下来,未来可以复用同一个角色身份。这种一致性会让 talking avatar 像一个真正的内容资产,而不是一次性的特效。
Talking Avatar 检查清单
导出前可以检查:
- 脚本已经拆成适合视频的小段。
- 声音表演本身已经可用。
- Avatar 图片清楚展示了脸或角色。
- 声音和图片像同一个角色。
- 口型同步和整体节奏一起检查过。
- 导出片段适合即将发布的渠道。
Talking avatar 最强的做法,是把它当成“声音驱动的视频”。先把表演做好,再让视觉角色把这段表演带到屏幕上。