
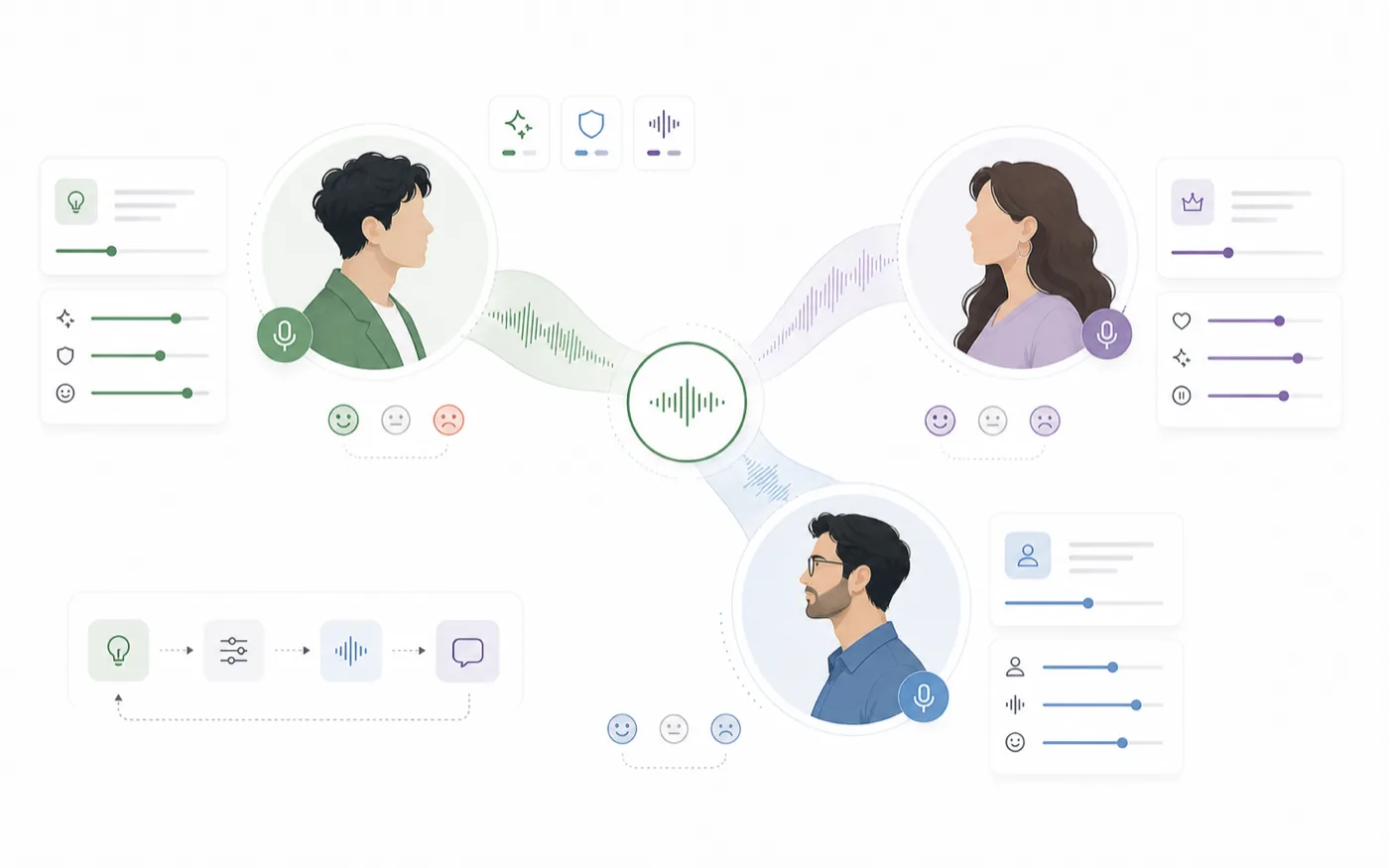
当现成音色“差不多但不够准”时,AI voice design 会很有用。你不需要在几百个音色里反复找,而是可以描述角色、提供视觉参考,然后生成更贴合角色方向的新音色。
RoleTTS Voice Design 适合放在选角和正式制作之间。你可以把角色 brief 变成音色方向,用短脚本试听,再把结果带进后续声音工作流。
先定义角色,而不是先定义声音
好的 voice design prompt 应该从角色要承担的内容任务开始。不要只写“好听”“专业”这类模糊词,它们可以作为补充,但不能真正定义角色。
一个更有效的 brief 会回答四个问题:
- 谁在说话?
- 现在是什么情绪?
- 说给谁听?
- 这个声音会出现在什么内容里?
比如,“适合 cozy fantasy 故事的冷静年轻旁白”就比“女声,温柔”更有方向。
把参考图当成创意方向
参考图不一定要是完整角色设定图。它可以是头像、情绪板、avatar 或视觉风格提示。关键是图片能传达年龄感、能量、类型和情绪。
如果你想让声音跟随明确角色设定,而不是只在固定目录里挑选,可以使用 AI Voice Design 页面。
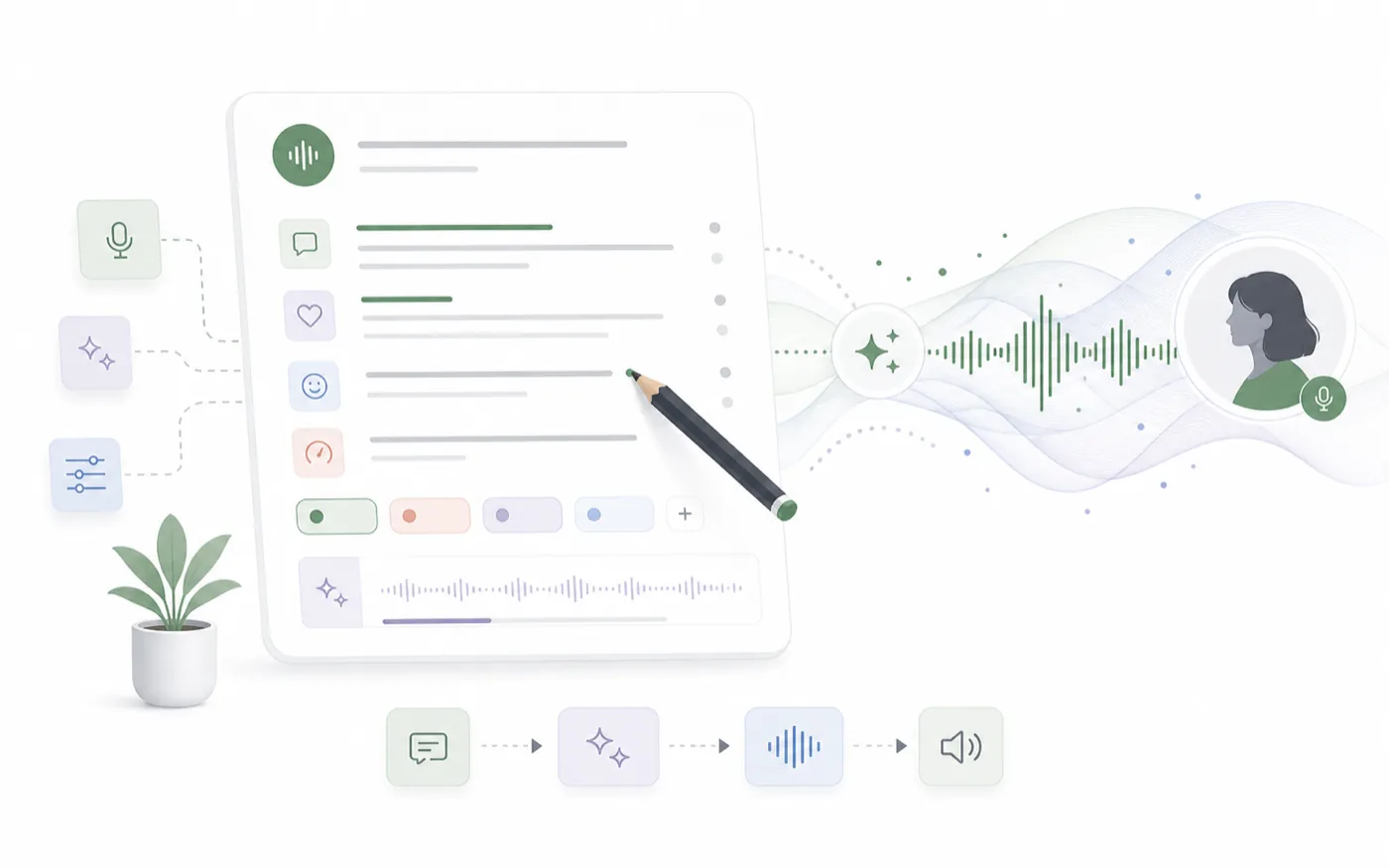
像写选角备注一样写 brief
音色 brief 要具体:
- “温暖、克制、略带神秘感。”
- “节奏快、明亮、自信,适合短视频。”
- “轻声但情绪表达直接。”
- “适合 fantasy 对白的年轻英雄主角声音。”
这些短语可以更好地定义表演方向,比重复堆叠形容词的长段落更有效。
用能暴露问题的脚本试听
一个声音可能在单句里很好听,但放到真实内容里就不适合。测试脚本应该代表真实使用场景。
故事内容可以放一条描述句和一条对白。产品解释可以放一句带专业词的内容。角色内容可以放一句带情绪或冲突的台词。
按任务判断音色
不要只问“好不好听”,要看它能不能完成任务:
- 对目标受众是否清晰?
- 是否符合角色年龄和性格?
- 长句里是否还能保持表达?
- 如果连续做十个场景,这个声音还能不能稳定?
从音色设计进入正式制作
当设计出来的声音可用后,可以把它带入更完整的工作流。你可以用它做 AI Text to Speech,保存到音色库,或者结合角色图像生成 Talking Avatar。

AI Voice Design 检查清单
保存音色前,可以检查:
- 角色 brief 足够具体。
- 参考图支持预期氛围。
- 测试脚本接近真实内容。
- 音色不只在一句话里可用。
- 这个结果在你的音色库里有明确用途。
Voice design 的价值不是随机生成声音,而是更像选角。先定义角色,再测试表演,最后只保留能持续服务内容的声音。